
RL10 - Actor-Critic 方法
约 424 字大约 1 分钟
- actor: 对应 policy update
- critic: 对应 policy evaluation 或者 value evaluation

显然,是在基于 策略梯度上升 算法的基础上,将对于 Q 值的估计通过一个网络来进行描述,这个便成为 critic, 而对应的策略梯度上升算法就是对应 actor。

1. The simplest actor-critic (QAC)


2. Advantage actor-critic (A2C)
核心思想:在 QAC 的基础上来引入偏置量(baseline),从而减小方差,提升采样的效率。
2.1 baseline
在策略梯度算法中引入一个 baseline, 不会影响所求的梯度。
即:
证明:
要证明加入baseline成立,只需要保证:
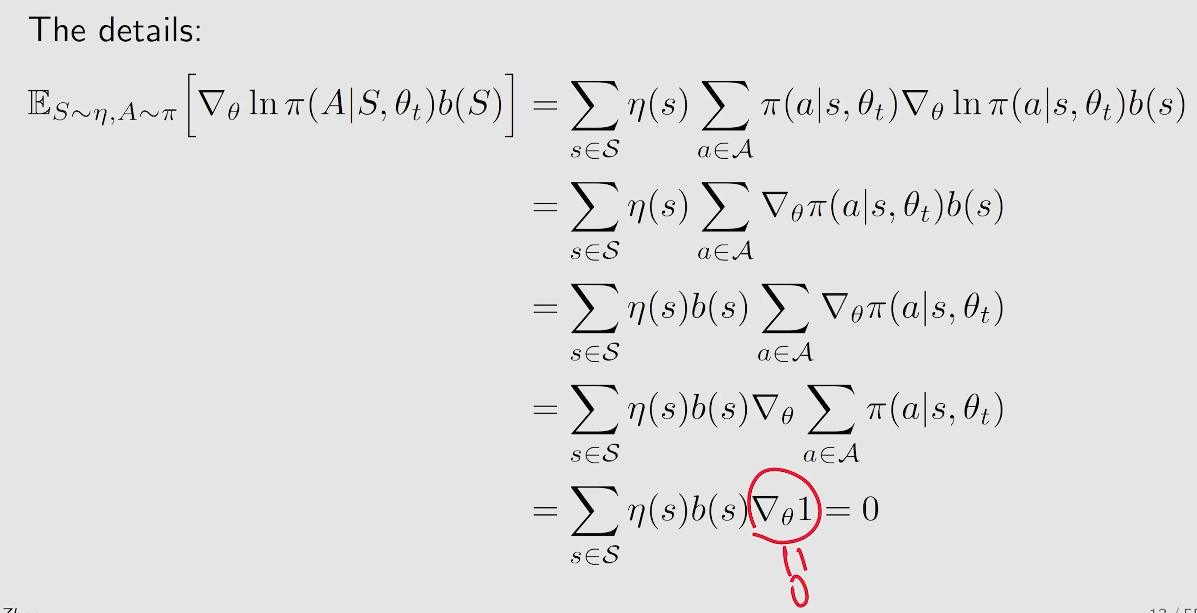
作用:
因此,我们需要找到一个 baseline 来保证这个梯度的方差最小即可。
2.2 最好的 baseline

在实际情况中,我们通常将 baseline 设置为
2.3 对应算法



3. off-policy actor-critic
通过 重要性采样 的方法,将处于 另一分布下 的策略所采集的数据来 运用到 策略更新 中。
3.1 重要性采样 (Importance sampling)



3.2 off-policy




3.3 伪代码

4. Deterministic actor-critic (DPG)
.png)

