
Javassm - Bean相关分析
Bean工厂与Bean定义
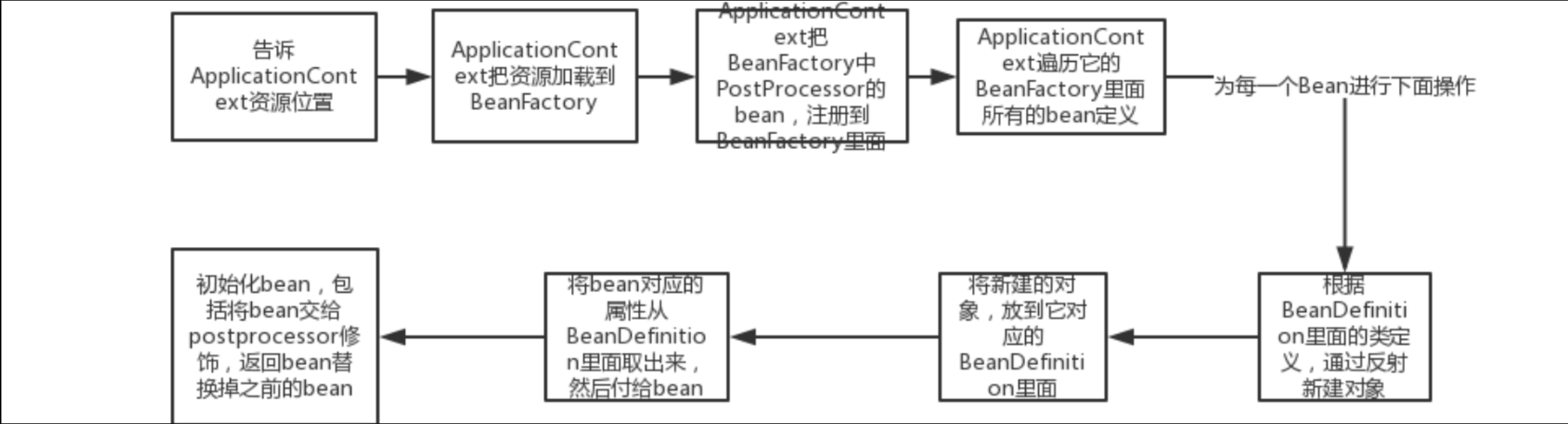
实际上我们之前的所有操作都离不开一个东西,那就是IoC容器,那么它到底是如何实现呢?这一部分我们将详细介绍,首先我们大致了解一下ApplicationContext的加载流程:

BeanFactory
首先,容器既然要管理Bean,那么肯定需要一个完善的管理机制
实际上,对Bean的管理都是依靠BeanFactory在进行,顾名思义BeanFactory就是对Bean进行生产和管理的工厂,我们可以尝试自己创建和使用BeanFactory对象:
public static void main(String[] args) {
BeanFactory factory = new DefaultListableBeanFactory(); //这是BeanFactory的一个默认实现类
System.out.println("获取Bean对象:"+factory.getBean("lbwnb")); //我们可以直接找工厂获取Bean对象
}
我们可以直接找Bean工厂索要对象,只不过在一开始,工厂并不知道自己需要生产什么,可以生产什么
我们只有告诉工厂我们要生产什么,怎么生产,工厂才能开工:
public static void main(String[] args) {
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
// 这是BeanFactory的一个默认实现类
BeanDefinition definition = BeanDefinitionBuilder
// 使用BeanDefinitionBuilder快速创建Bean定义
.rootBeanDefinition(Student.class) // Bean的类型
.setScope("prototype") // 设置作用域为原型模式
.getBeanDefinition(); // 生成此Bean定义
factory.registerBeanDefinition("lbwnb", definition);
// 向工厂注册Bean此定义,并设定Bean的名称
System.out.println(factory.getBean("lbwnb"));
// 现在就可以拿到了
}
实际上,我们的ApplicationContext中就维护了一个AutowireCapableBeanFactory对象:
public abstract class AbstractRefreshableApplicationContext extends AbstractApplicationContext {
@Nullable
private volatile DefaultListableBeanFactory beanFactory; //默认构造后存放在这里的是一个DefaultListableBeanFactory对象
...
@Override
public final ConfigurableListableBeanFactory getBeanFactory() { //getBeanFactory就可以直接得到上面的对象了
DefaultListableBeanFactory beanFactory = this.beanFactory;
if (beanFactory == null) {
throw new IllegalStateException("BeanFactory not initialized or already closed - " +
"call 'refresh' before accessing beans via the ApplicationContext");
}
return beanFactory;
}
}
可以尝试获取一下:
ApplicationContext context = new ClassPathXmlApplicationContext("application.xml");
//我们可以直接获取此对象
System.out.println(context.getAutowireCapableBeanFactory());
正是因为这样,ApplicationContext才具有了管理和生产Bean对象的能力。
不过,我们的配置可能是XML、可能是配置类,那么Spring要如何进行解析,将这些变成对应的BeanDefinition对象呢?
使用BeanDefinitionReader就可以:
public static void main(String[] args) {
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
// 比如我们要读取XML配置,我们直接使用XmlBeanDefinitionReader就可以快速进行扫描
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory);
// 加载此XML文件中所有的Bean定义到Bean工厂中
reader.loadBeanDefinitions(new ClassPathResource("application.xml"));
// 可以看到能正常生产此Bean的实例对象
System.out.println(factory.getBean(Student.class));
}
ApplicationContext实现方式
因此,针对于不同类型的配置方式,ApplicationContext有着多种实现,其中常用的有:
ClassPathXmlApplicationContext:适用于类路径下的XML配置文件。FileSystemXmlApplicationContext:适用于非类路径下的XML配置文件。AnnotationConfigApplicationContext:适用于注解配置形式。
比如ClassPathXmlApplicationContext在初始化的时候就会创建一个对应的XmlBeanDefinitionReader进行扫描:
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// 为给定的BeanFactory创建XmlBeanDefinitionReader便于读取XML中的Bean配置
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// 各种配置,忽略掉
beanDefinitionReader.setEnvironment(this.getEnvironment());
...
// 配置完成后,直接开始加载XML文件中的Bean定义
loadBeanDefinitions(beanDefinitionReader);
}
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
Resource[] configResources = getConfigResources(); //具体加载过程我就不详细介绍了
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
String[] configLocations = getConfigLocations();
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
现在,我们就已经知道,Bean实际上是一开始通过BeanDefinitionReader进行扫描,然后将所有Bean以BeanDefinition对象的形式注册到对应的BeanFactory中进行集中管理
我们使用的ApplicationContext实际上内部就有一个BeanFactory在进行Bean管理,这样容器才拥有了最基本的Bean管理功能。
BeanFactory继承
当然,BeanFactory还可以具有父子关系,其中最关键的作用就是继承父容器中所有的Bean定义
这样的话,如果我们想要创建一个新的BeanFactory并且默认具有其他BeanFactory中所有的Bean定义外加一些其他的,那么就可以采用这种形式,这是很方便的。
我们可以来尝试一下,创建两个工厂:
public class Main {
public static void main(String[] args) {
DefaultListableBeanFactory factoryParent = new DefaultListableBeanFactory();
DefaultListableBeanFactory factoryChild = new DefaultListableBeanFactory();
// 在父工厂中注册A
factoryParent.registerBeanDefinition("a", new RootBeanDefinition(A.class));
// 在子工厂中注册B、C
factoryChild.registerBeanDefinition("b", new RootBeanDefinition(B.class));
factoryChild.registerBeanDefinition("c", new RootBeanDefinition(C.class));
// 最后设定子工厂的父工厂
factoryChild.setParentBeanFactory(factoryParent);
}
static class A{ }
static class B{ }
static class C{ }
}
现在我们来看看是不是我们想的那样:
System.out.println(factoryChild.getBean(A.class)); //子工厂不仅能获取到自己的,也可以拿到父工厂的
System.out.println(factoryChild.getBean(B.class));
System.out.println(factoryChild.getBean(C.class));
System.out.println(factoryParent.getBean(B.class)); //注意父工厂不能拿到子工厂的,就像类的继承一样
同样的,我们在使用ApplicationContext时,也可以设定这样的父子关系,效果相同:
public static void main(String[] args) {
ApplicationContext contextParent = new ClassPathXmlApplicationContext("parent.xml");
ApplicationContext contextChild = new ClassPathXmlApplicationContext(new String[]{"child.xml"}, contextParent); //第一个参数只能用数组,奇怪
}
当然,除了这些功能之外,BeanFactory还提供了很多其他的管理Bean定义的方法,比如移除Bean定义、拷贝Bean定义、销毁单例Bean实例对象等功能,这里就不一一列出了,各位小伙伴自己调用一下测试就可以了,很简单。
单例Bean的创建与循环依赖
前面我们讲解了配置的Bean是如何被读取并加载到容器中的,接着我们来了解一下Bean实例对象是如何被创建并得到的
我们知道,如果要得到一个Bean的实例很简单,通过getBean方法就可以直接拿到了:
ApplicationContext context = new ClassPathXmlApplicationContext("application.xml");
System.out.println(context.getBean(Student.class));
//通过此方法就能快速得到
那么,一个Bean的实例对象到底是如何创建出来的呢?
BeanFactory分析
我们还要继续对我们之前讲解的BeanFactory进行深入介绍。
我们可以直接找到BeanFactory接口的一个抽象实现AbstractBeanFactory类,它实现了getBean()方法:
public Object getBean(String name) throws BeansException {
// 套娃开始了,做好准备
return this.doGetBean(name, (Class)null, (Object[])null, false);
}
那么我们doGetBean()接着来看方法里面干了什么,这个方法比较长,我们分段进行讲解:
protected <T> T doGetBean(String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly) throws BeansException {
String beanName = this.transformedBeanName(name);
// 虽然这里直接传的就是name,但是万一是别名呢,所以还得要解析一下变成原本的Bean名字
Object sharedInstance = this.getSingleton(beanName);
// 首先直接获取单例Bean对象
Object beanInstance;
if (sharedInstance != null && args == null) {
// 判断是否成功获取到共享的单例对象
...
}else{
...
}
}
因为所有的Bean默认都是单例模式,对象只会存在一个
因此它会先调用父类的getSingleton()方法来直接获取单例对象,如果有的话,就可以直接拿到Bean的实例。
如果Bean不是单例模式,那么会进入else代码块。
这一部分我们先来看单例模式下的处理,其实逻辑非常简单:
protected <T> T doGetBean(String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly) throws BeansException {
...
if (sharedInstance != null && args == null) {
if (this.logger.isTraceEnabled()) {
// 这里会判断Bean是否为正在创建状态,为什么会有这种状态呢?我们会在后面进行介绍
if (this.isSingletonCurrentlyInCreation(beanName)) {
this.logger.trace("Returning eagerly cached instance of singleton bean '" + beanName + "' that is not fully initialized yet - a consequence of a circular reference");
} else {
this.logger.trace("Returning cached instance of singleton bean '" + beanName + "'");
}
}
//这里getObjectForBeanInstance会进行最终处理
//因为Bean有两个特殊的类型,工厂Bean和空Bean,所以说需要单独处理
//如果是普通Bean直接原样返回beanInstance接收到最终结果
beanInstance = this.getObjectForBeanInstance(sharedInstance, name, beanName, (RootBeanDefinition)null);
} else {
...
}
//最后还会进行一次类型判断,如果都没问题,直接返回beanInstance作为结果,我们就得到Bean的实例对象了
return this.adaptBeanInstance(name, beanInstance, requiredType);
}
实际上整个单例Bean的创建路线还是很清晰的,并没有什么很难理解的地方,在正常情况下,其实就是简单的创建对象实例并返回即可。
循环依赖的解决
其中最关键的是它对于循环依赖的处理。
我们发现,在上面的代码中,得到单例对象后,会有一个很特殊的判断isSingletonCurrentlyInCreation,这个是干嘛的?
对象不应该直接创建出来吗?为什么会有这种正在创建的状态呢?我们来探究一下。
开始之前先给大家提个问题:
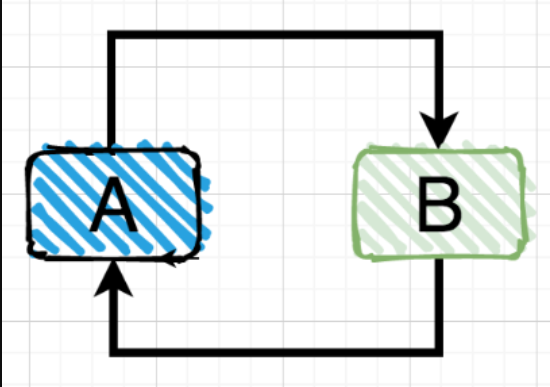
现在有两个Bean,A和B都是以原型模式进行创建,而A中需要注入B,B中需要注入A,这时就会出现A还未创建完成,就需要B,而B这时也没创建完成,因为B需要A,而A等着B,B又等着A,这样就只能无限循环下去了(就像死锁那种感觉)所以就出现了循环依赖的问题(同理,一个对象注入自己,还有三个对象之间,甚至多个对象之间也会出现这种情况)
但是,在单例模式下,由于每个Bean只会创建一个实例,只要能够处理好对象之间的引用关系,Spring完全有机会解决单例对象循环依赖的问题。
我们回到一开始的getSingleton()方法中,研究一下它到底是如何处理循环依赖的,它是可以自动解决循环依赖问题的:
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
// 先从第一层列表中拿Bean实例,拿到直接返回
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {
// 如果第一层拿不到,并且已经认定为处于循环状态,看看第二层有没有
singletonObject = this.earlySingletonObjects.get(beanName);
// 要是还是没有,继续往下
if (singletonObject == null && allowEarlyReference) {
synchronized(this.singletonObjects) {
// 加锁再执行一次上述流程
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 仍然没有获取到实例,只能从singletonFactory中获取了
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
// 丢进earlySingletonObjects中,下次就可以直接在第二层拿到了
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
看起来很复杂,实际上它使用了三级缓存的方式来处理循环依赖的问题,包括:
singletonObjects,用于保存实例化、注入、初始化完成的 bean 实例earlySingletonObjects,用于保存实例化完成的 bean 实例singletonFactories,在初始创建Bean对象时都会生成一个对应的单例工厂用于获取早期对象
我们先来画一个流程图理清整个过程:
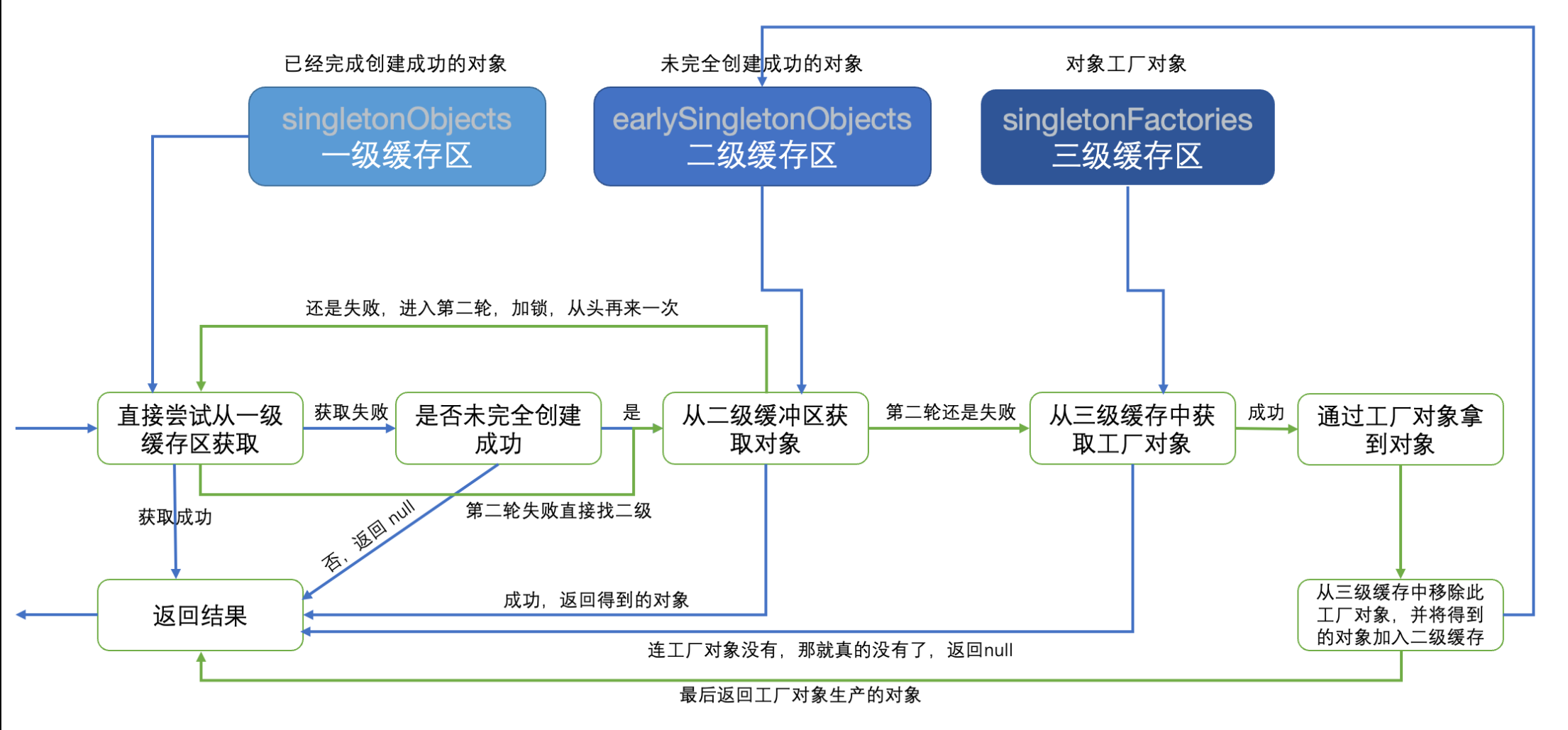
我们在了解这个流程之前,一定要先明确,单例Bean对象的获取,会有哪些结果,首先就是如果我们获取的Bean压根就没在工厂中注册,那得到的结果肯定是null;
其次,如果我们获取的Bean已经注册了,那么肯定就可以得到这个单例对象,只是不清楚创建到哪一个阶段了。
现在我们根据上面的流程图,来模拟一下A和B循环依赖的情况:
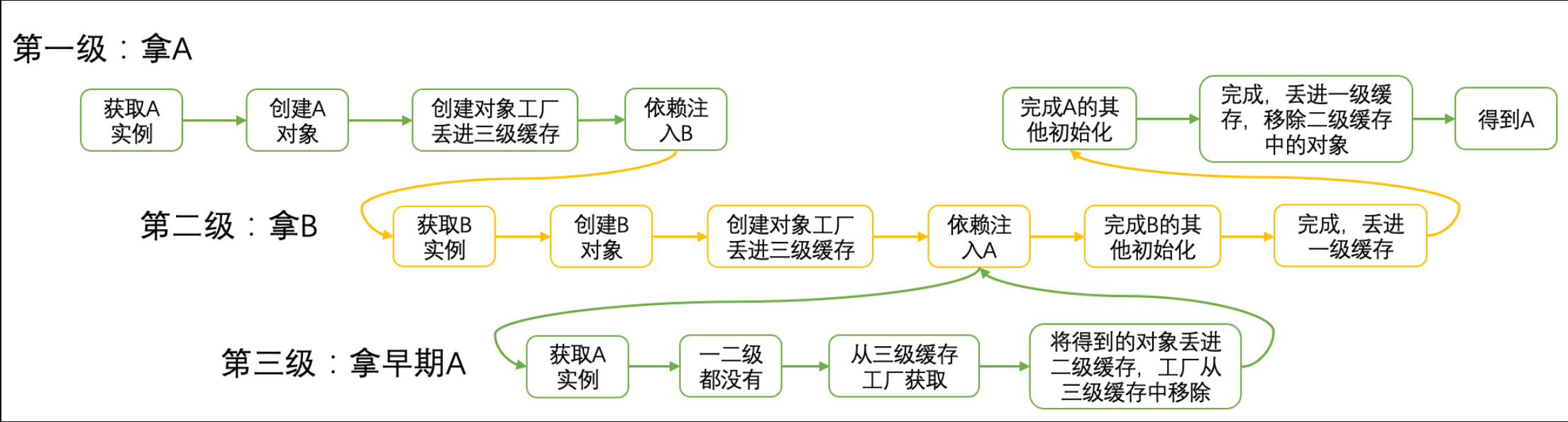
看起来似乎两级缓存也可以解决问题啊,干嘛搞三层而且还搞个对象工厂?这不是多此一举吗?
实际上这是为了满足Bean的生命周期而做的,通过工厂获取早期对象代码如下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
// 这里很关键,会对一些特别的BeanPostProcessor进行处理,比如AOP代理相关的,如果这个Bean是被AOP代理的,我们需要得到的是一个经过AOP代理的对象,而不是直接创建出来的对象,这个过程需要BeanPostProcessor来完成(AOP产生代理对象的逻辑是在属性填充之后,因此只能再加一级进行缓冲)
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
我们会在后面的部分中详细介绍BeanPostProcessor以及AOP的实现原理,届时各位再回来看就会明白了。