
Java - 集合类 4
集合类 4
Map
映射指两个元素的之间相互“对应”的关系,也就是说,我们的元素之间是两两对应的,是以键值对的形式存在。
Map 就是为了实现这种数据结构而存在的,我们通过保存键值对的形式来存储映射关系,就可以轻松地通过键找到对应的映射值
Map 并不是 Collection 体系下的接口,而是单独的一个体系,因为操作特殊
Map 基本定义
在 Map 中,这些映射关系被存储为键值对,Map 接口中定义的操作:
// Map并不是Collection体系下的接口,而是单独的一个体系,因为操作特殊
// 这里需要填写两个泛型参数,
// 其中K就是键的类型,V就是值的类型,
// 比如上面的学生信息,ID一般是int,那么键就是Integer类型的,而值就是学生信息,所以说值是学生对象类型的
public interface Map<K,V> {
//-------- 查询相关操作 --------
//获取当前存储的键值对数量
int size();
//是否为空
boolean isEmpty();
//查看Map中是否包含指定的键
boolean containsKey(Object key);
//查看Map中是否包含指定的值
boolean containsValue(Object value);
//通过给定的键,返回其映射的值
V get(Object key);
//-------- 修改相关操作 --------
//向Map中添加新的映射关系,也就是新的键值对
V put(K key, V value);
//根据给定的键,移除其映射关系,也就是移除对应的键值对
V remove(Object key);
//-------- 批量操作 --------
//将另一个Map中的所有键值对添加到当前Map中
void putAll(Map<? extends K, ? extends V> m);
//清空整个Map
void clear();
//-------- 其他视图操作 --------
//返回Map中存放的所有键,以Set形式返回
Set<K> keySet();
//返回Map中存放的所有值
Collection<V> values();
//返回所有的键值对,这里用的是内部类Entry在表示
Set<Map.Entry<K, V>> entrySet();
//这个是内部接口Entry,表示一个键值对
interface Entry<K,V> {
//获取键值对的键
K getKey();
//获取键值对的值
V getValue();
//修改键值对的值
V setValue(V value);
//判断两个键值对是否相等
boolean equals(Object o);
//返回当前键值对的哈希值
int hashCode();
...
}
...
}
HashMap
底层采用哈希表实现
基本示例
public static void main(String[] args) { Map<Integer, String> map = new HashMap<>(); map.put(1, "小明"); //使用put方法添加键值对,返回值我们会在后面讨论 map.put(2, "小红"); System.out.println(map.get(2)); //使用get方法根据键获取对应的值 }Map中无法添加相同的键,同样的键只能存在一个,即使值不同。如果出现键相同的情况,那么会覆盖掉之前的为了防止意外将之前的键值对覆盖掉,我们可以使用
putIfAbsent:public static void main(String[] args) { Map<Integer, String> map = new HashMap<>(); map.put(1, "小明"); map.putIfAbsent(1, "小红"); //Java8 新增操作,只有在不存在相同键的键值对时才会存放 System.out.println(map.get(1)); }我们在获取一个不存在的映射时,默认会返回
null作为结果:public static void main(String[] args) { Map<Integer, String> map = new HashMap<>(); map.put(1, "小明"); //Map中只有键为1的映射 System.out.println(map.get(3)); //此时获取键为3的值,那肯定是没有的,所以说返回null }我们也可以为这种情况添加一个预备方案
getOrDefault,当Map中不存在时,可以返回一个备选的返回值:public static void main(String[] args) { Map<Integer, String> map = new HashMap<>(); map.put(1, "小明"); System.out.println(map.getOrDefault(3, "备胎")); //Java8新增操作,当不存在对应的键值对时,返回备选方案 }因为
HashMap底层采用哈希表实现,所以不维护顺序,我们在获取所有键和所有值时,可能会是乱序的如果需要维护顺序,我们同样可以使用
LinkedHashMap,它的内部对插入顺序进行了维护
HashMap 底层实现
HashMap 的底层实现是由 哈希表 实现的。
哈希表可能会出现哈希冲突,这样保存的元素数量就会存在限制,而我们可以通过连地址法解决这种问题,最后哈希表就长这样了:
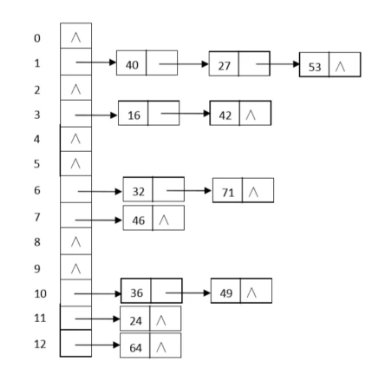
实际上这个表就是一个存放头结点的数组+若干结点,而HashMap也是这样的,我们来看看这里面是怎么定义的:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
...
static class Node<K,V> implements Map.Entry<K,V> {
//内部使用结点,实际上就是存放的映射关系
final int hash;
final K key;
//跟我们之前不一样,我们之前一个结点只有键,而这里的结点既存放键也存放值,当然计算哈希还是使用键
V value;
Node<K,V> next;
...
}
...
transient Node<K,V>[] table;
//这个就是哈希表本体了,可以看到跟我们之前的写法是一样的,也是头结点数组,只不过HashMap中没有设计头结点(相当于没有头结点的链表)
final float loadFactor;
//负载因子,这个东西决定了HashMap的扩容效果
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
//当我们创建对象时,会使用默认的负载因子,值为0.75
}
...
}
可以看到,实际上底层大致结构跟我们之前学习的差不多,只不过多了一些特殊的东西:
- HashMap支持自动扩容,哈希表的大小并不是一直不变的,否则太过死板
- HashMap并不是只使用简单的链地址法,当链表长度到达一定限制时,会转变为效率更高的红黑树结构
put 方法
public V put(K key, V value) {
//这里计算完键的哈希值之后,调用的另一个方法进行映射关系存放
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//如果底层哈希表没初始化,先初始化
n = (tab = resize()).length;
// 通过resize方法初始化底层哈希表,初始容量为16,
// 后续会根据情况扩容,底层哈希表的长度永远是2的n次方
// 因为传入的哈希值可能会很大,这里同样是进行取余操作
// (n - 1) & hash 等价于 hash % n
// 这里的i就是最终得到的下标位置了
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 如果这个位置上什么都没有,那就直接放一个新的结点
else {
// 这种情况就是哈希冲突了
Node<K,V> e; K k;
// 如果上来第一个结点的键的哈希值跟当前插入的键的哈希值相同,键也相同,说明已经存放了相同键的键值对了,那就执行覆盖操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//这里直接将待插入结点等于原本冲突的结点,一会直接覆盖
else if (p instanceof TreeNode)
//如果第一个结点是TreeNode类型的,说明这个链表已经升级为红黑树了
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//在红黑树中插入新的结点
else {
for (int binCount = 0; ; ++binCount) {
//普通链表就直接在链表尾部插入
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//找到尾部,直接创建新的结点连在后面
if (binCount >= TREEIFY_THRESHOLD - 1)
//如果当前链表的长度已经很长了,达到了阈值
treeifyBin(tab, hash);
//那么就转换为红黑树来存放
break;
//直接结束
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
//同样的,如果在向下找的过程中发现已经存在相同键的键值对了,直接结束,让p等于e一会覆盖就行了
break;
p = e;
}
}
if (e != null) {
// 如果e不为空,只有可能是前面出现了相同键的情况,其他情况e都是null,所有直接覆盖就行
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
//覆盖之后,会返回原本的被覆盖值
}
}
++modCount;
if (++size > threshold)
//键值对size计数自增,如果超过阈值,会对底层哈希表数组进行扩容
resize();
//调用resize进行扩容
afterNodeInsertion(evict);
return null;
//正常插入键值对返回值为null
}
resize 方法
resize 在初始化时会调用一次,此外在每次扩容时会调用。
根据上面的推导,我们在正常插入一个键值对时,会得到 null 返回值,而冲突时会得到一个被覆盖的值.
HashMap的一个链表长度过大时,会自动转换为红黑树:
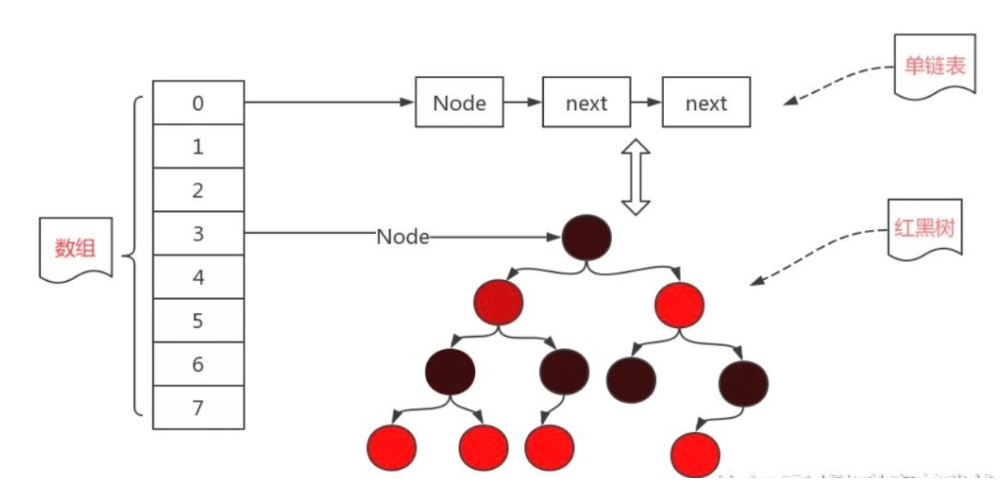
但是这样始终治标不治本,受限制的始终是底层哈希表的长度,我们还需要进一步对底层的这个哈希表进行扩容才可以从根本上解决问题,我们来看看resize()方法:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//先把下面这几个旧的东西保存一下
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0; //这些是新的容量和扩容阈值
if (oldCap > 0) {
//如果旧容量大于0,那么就开始扩容
if (oldCap >= MAXIMUM_CAPACITY) {
// 如果旧的容量已经大于最大限制了,
// 那么直接给到 Integer.MAX_VALUE
threshold = Integer.MAX_VALUE;
return oldTab;
//这种情况不用扩了
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//新的容量等于旧容量的2倍,同样不能超过最大值
newThr = oldThr << 1;
//新的阈值也提升到原来的两倍
}
else if (oldThr > 0)
// 旧容量不大于0只可能是还没初始化
// 这个时候如果阈值大于0,直接将新的容量变成旧的阈值
newCap = oldThr;
else {
// 默认情况下阈值也是0,也就是我们刚刚无参 new 出来的时候
newCap = DEFAULT_INITIAL_CAPACITY;
// 新的容量直接等于默认容量16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
// 阈值为负载因子乘以默认容量,负载因子默认为0.75
// 也就是说只要整个哈希表用了75%的容量,那么就进行扩容,至于为什么默认是0.75,原因很多,这里就不解释了,
// 反正作为新手,这些都是大佬写出来的,我们用就完事。
}
...
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; //将底层数组变成新的扩容之后的数组
if (oldTab != null) { //如果旧的数组不为空,那么还需要将旧的数组中所有元素全部搬到新的里面去
...
//详细过程就不介绍了
}
}
LinkedHashMap
HashMap 并不会维持插入的顺序,LinkedHashMap 是直接继承自HashMap,具有 HashMap 的全部性质,同时得益于每一个节点都是一个双向链表,在插入键值对时,同时保存了插入顺序
static class Entry<K,V> extends HashMap.Node<K,V> {
// LinkedHashMap中的结点实现
Entry<K,V> before, after;
// 这里多了一个指向前一个结点和后一个结点的引用
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
这样我们在遍历 LinkedHashMap 时,顺序就同我们的插入顺序一致。
当然,也可以使用访问顺序,也就是说对于刚访问过的元素,会被排到最后一位。
TreeMap
它的内部直接维护了一个红黑树(没有使用哈希表)
因为它会将我们插入的结点按照规则进行排序,所以说直接采用红黑树会更好,我们在创建时,直接给予一个比较规则即可,跟之前的 TreeSet 是一样的
Map 的一些方法
compute
compute 会将指定 Key 的值进行重新计算,若 Key 不存在,v 会返回 null
computeIfPresent 当 Key 存在时存在则计算并赋予新的值
computeIfAbsent 不存在Key时,计算并将键值对放入Map中:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.compute(1, (k, v) -> {
//compute 会将指定Key的值进行重新计算,若Key不存在,v会返回null
return v+"M";
//这里返回原来的value+M
});
map.computeIfPresent(1, (k, v) -> {
// 当Key存在时存在则计算并赋予新的值
return v+"M"; //这里返回原来的value+M
});
System.out.println(map);
map.put(1, "A");
map.put(2, "B");
map.computeIfAbsent(0, (k) -> {
//若不存在则计算并插入新的值
return "M"; //这里返回M
});
System.out.println(map);
}
merge
merge方法用于处理数据:
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("yoni", "English", 80),
new Student("yoni", "Chiness", 98),
new Student("yoni", "Math", 95),
new Student("taohai.wang", "English", 50),
new Student("taohai.wang", "Chiness", 72),
new Student("taohai.wang", "Math", 41),
new Student("Seely", "English", 88),
new Student("Seely", "Chiness", 89),
new Student("Seely", "Math", 92)
);
Map<String, Integer> scoreMap = new HashMap<>();
//merge方法可以对重复键的值进行特殊操作,比如我们想计算某个学生的所有科目分数之后,那么就可以像这样:
students.forEach(student -> scoreMap.merge(student.getName(), student.getScore(), Integer::sum));
scoreMap.forEach((k, v) -> System.out.println("key:" + k + "总分" + "value:" + v));
}
static class Student {
private final String name;
private final String type;
private final int score;
public Student(String name, String type, int score) {
this.name = name;
this.type = type;
this.score = score;
}
public String getName() {
return name;
}
public int getScore() {
return score;
}
public String getType() {
return type;
}
}
replace
replace方法可以快速替换某个映射的值
public static void main(String[] args) {
Map<Integer , String> map = new HashMap<>();
map.put(0, "单走");
map.replace(0, ">>>"); //直接替换为新的
System.out.println(map);
}
也可以精准匹配:
public static void main(String[] args) {
Map<Integer , String> map = new HashMap<>();
map.put(0, "单走");
map.replace(0, "巴卡", "玛卡"); //只有键和值都匹配时,才进行替换
System.out.println(map);
}
包括 remove 方法,也支持键值同时匹配:
public static void main(String[] args) {
Map<Integer , String> map = new HashMap<>();
map.put(0, "单走");
map.remove(0, "单走"); //只有同时匹配时才移除
System.out.println(map);
}
HashSet 底层实现
它的底层很简单,底层是直接用 HashMap 套壳实现的。
因为 Set 只需要存储 Key 就行了,所以说这个对象当做每一个键值对的共享 Value
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map;
//对,你没看错,底层直接用 map 来做事
// 因为 Set 只需要存储 Key 就行了,所以说这个对象当做每一个键值对的共享 Value
private static final Object PRESENT = new Object();
// 直接构造一个默认大小为16负载因子0.75的HashMap
public HashSet() {
map = new HashMap<>();
}
...
// 你会发现所有的方法全是替身攻击
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
}
通过观察 HashSet 的源码发现,HashSet 几乎都在操作内部维护的一个HashMap ,也就是说,HashSet 只是一个表壳,而内部维护的 HashMap 才是灵魂!
就像你进了公司,在外面花钱请别人帮你写公司的业务,你只需要坐着等别人写好然后你自己拿去交差就行了。
所以说,HashSet 利用了 HashMap 内部的数据结构,轻松地就实现了 Set 定义的全部功能!
再来看 TreeSet,实际上用的就是我们的 TreeMap
LinkedSet 用的就是 LinkedMap